|
Seohyeon Cha I'm a second-year PhD student at UT Austin ECE, advised by Prof. Haris Vikalo. My research develops efficient, trustworthy AI for decentralized, resource-constrained systems — designing methods that preserve reliability under tight compute/memory/latency budgets, device heterogeneity, and non-stationary deployments. Previously, I completed my M.S. at the Advanced Radio Technology Lab, KAIST, where I also earned my B.S. in Electrical Engineering (Summa Cum Laude). |

|
Research Interests
|
News
|
Publications* indicates equal contribution. |
Preprints |
|
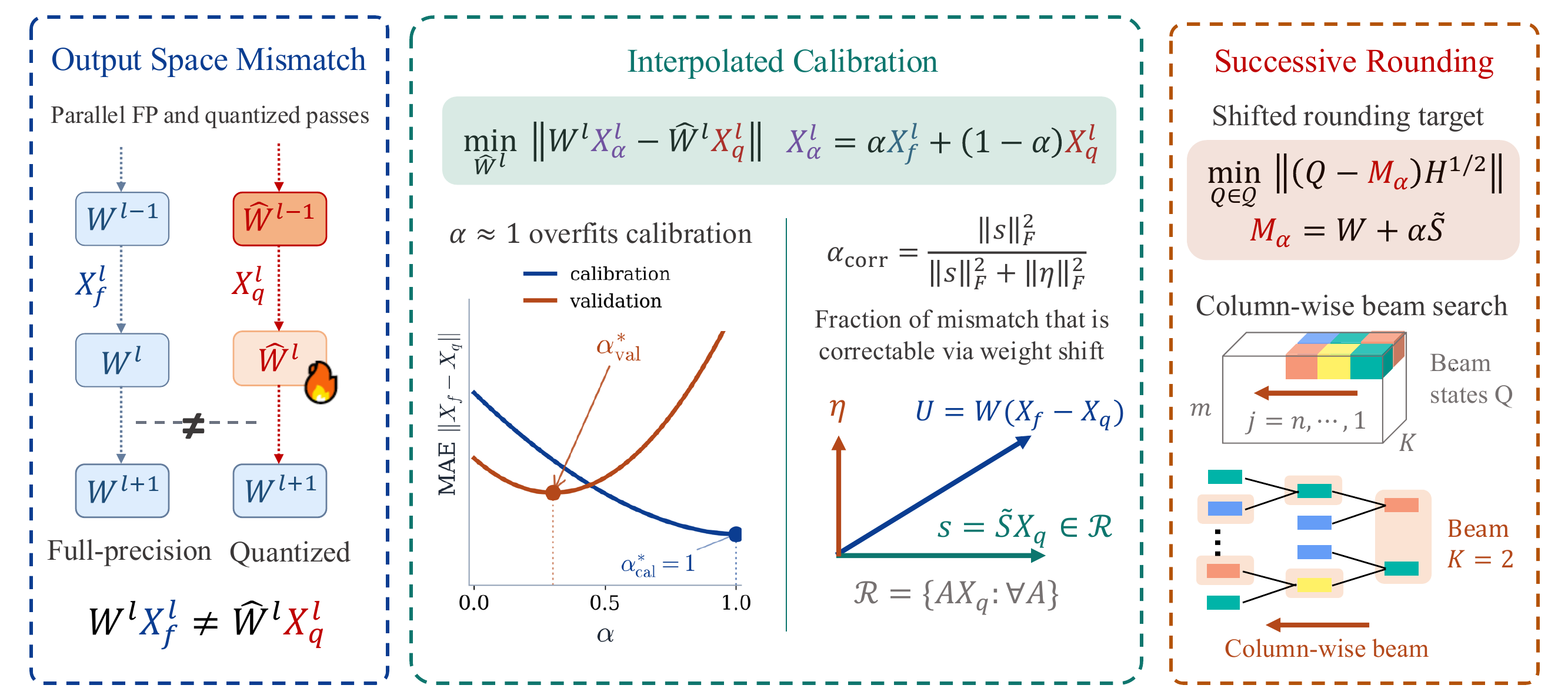
CoreQ: Learning-Free Mismatch Correction and Successive Rounding for Quantization
Seohyeon Cha, Huancheng Chen, Dongjun Kim, Haoran Zhang, Kevin Chan, Gustavo de Veciana, Haris Vikalo arXiv preprint, 2026 arXiv We introduce CoreQ, a learning-free PTQ framework that adaptively corrects sequential mismatch and navigates the compute–quality trade-off via successive rounding |
|
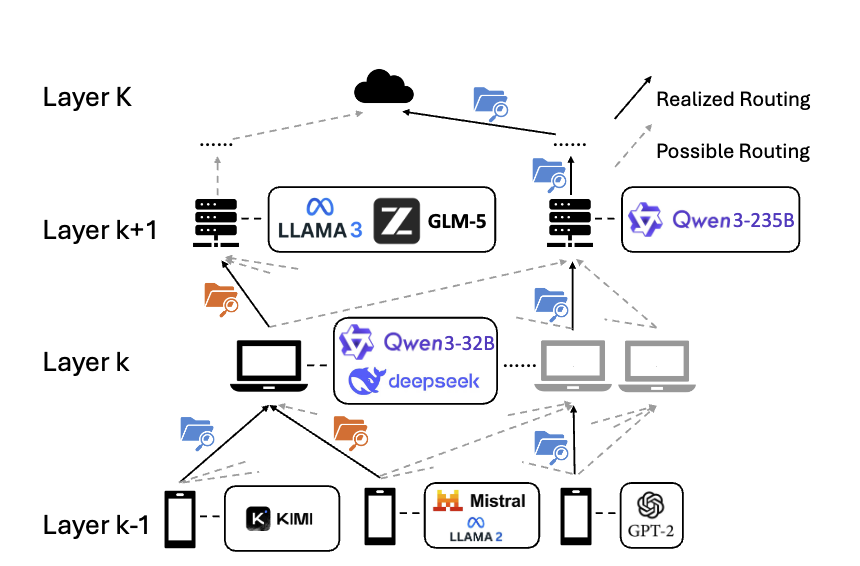
Online Learning for Multi-Layer Hierarchical Inference under Partial and Policy-Dependent Feedback
Haoran Zhang, Seohyeon Cha, H. Burak Beytur, Kevin S. Chan, Gustavo de Veciana, Haris Vikalo arXiv preprint, 2026 arXiv Online learning formulation of multi-layer hierarchical inference with recursively defined loss and terminal-only feedback, combined with a variance-reduced Lyapunov algorithm for long-term resource constraints. |
|
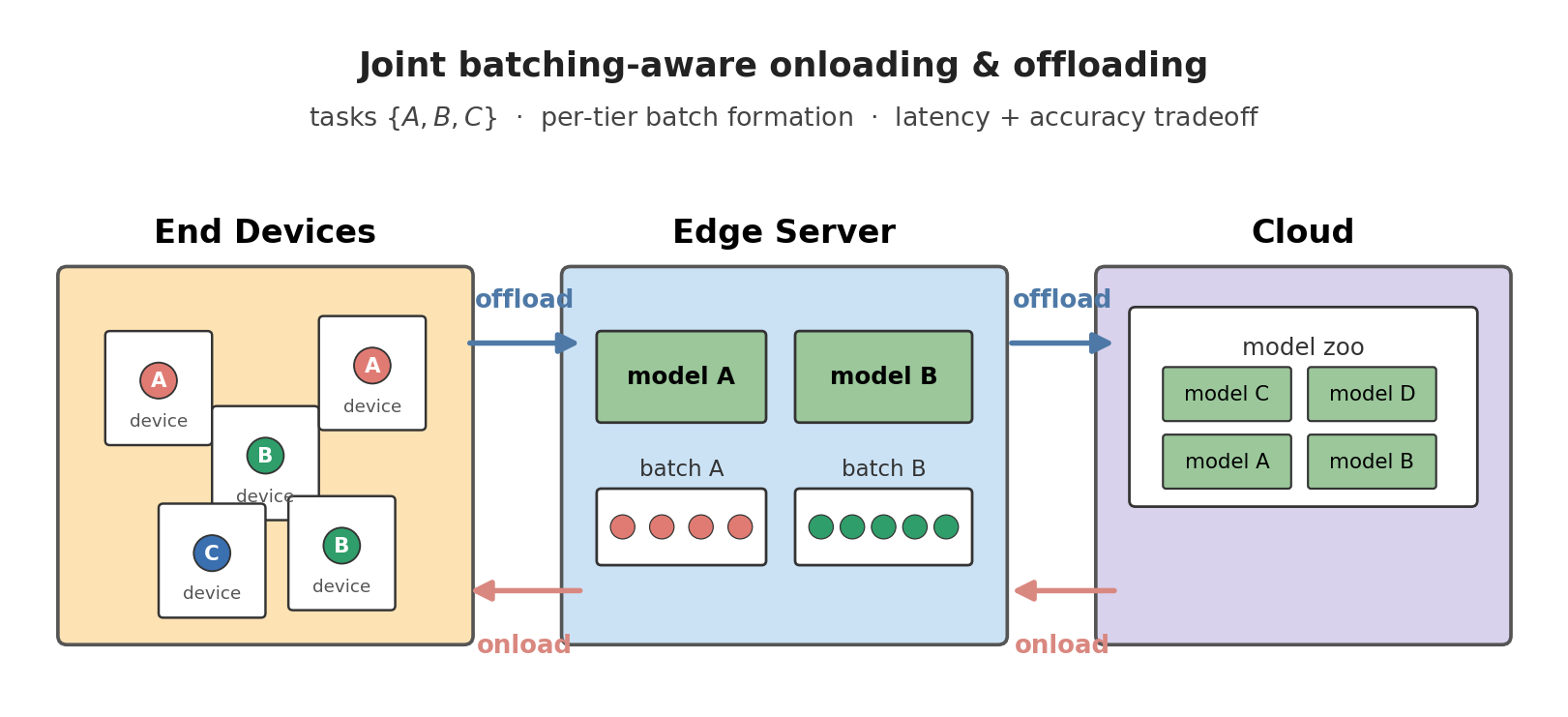
Batching-Aware Joint Model Onloading and Offloading for Hierarchical Multi-Task Inference
Seohyeon Cha, Kevin Chan, Gustavo de Veciana, Haris Vikalo arXiv preprint, 2025 arXiv Joint scheduling of on-device inference and edge offloading with explicit batching awareness across a hierarchy of multi-task models, to meet latency targets under mixed traffic. |
Journal Papers |
|
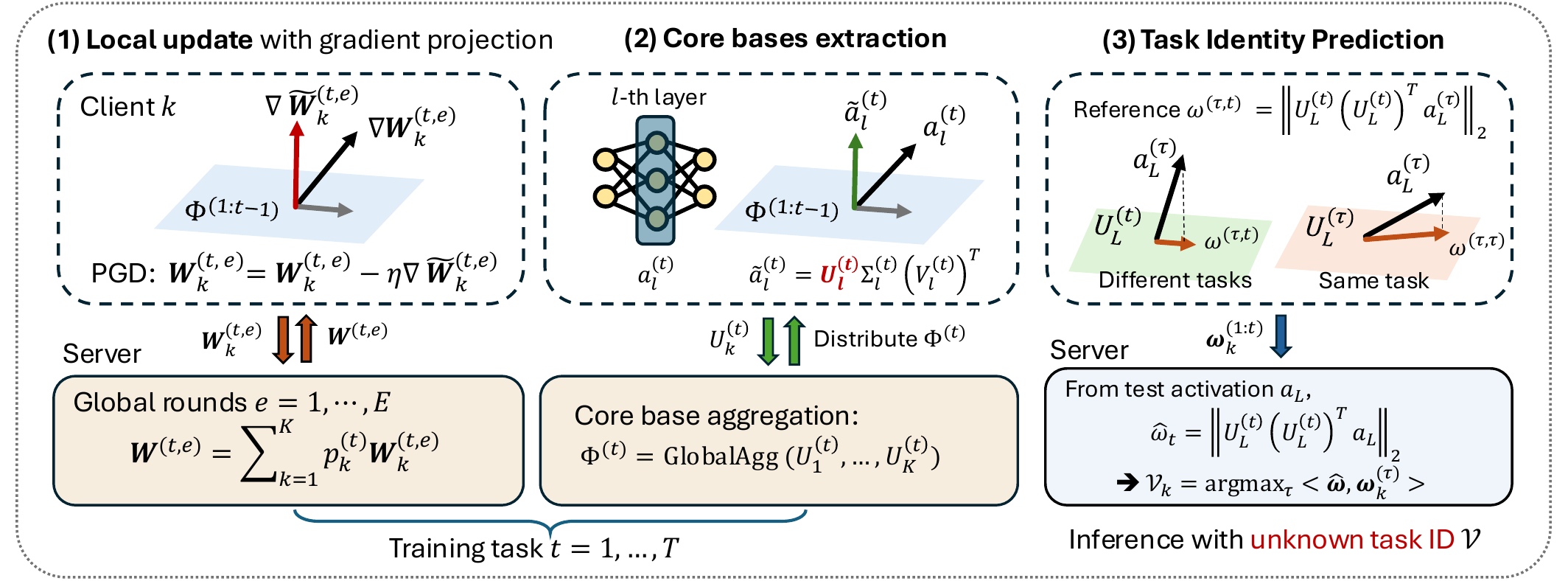
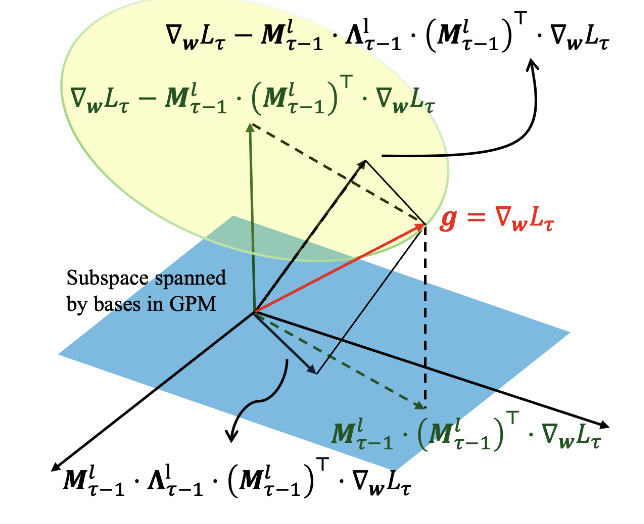
FedProTIP: Task-Agnostic Federated Continual Learning via Replay-Free Gradient Projection
Seohyeon Cha*, Huancheng Chen*, Haris Vikalo Transactions on Machine Learning Research, 2026 arXiv Federated continual learning without per-client replay buffers: projected-gradient updates combined with core-basis extraction and a lightweight task-identity predictor for privacy-preserving CL under device heterogeneity. |
|
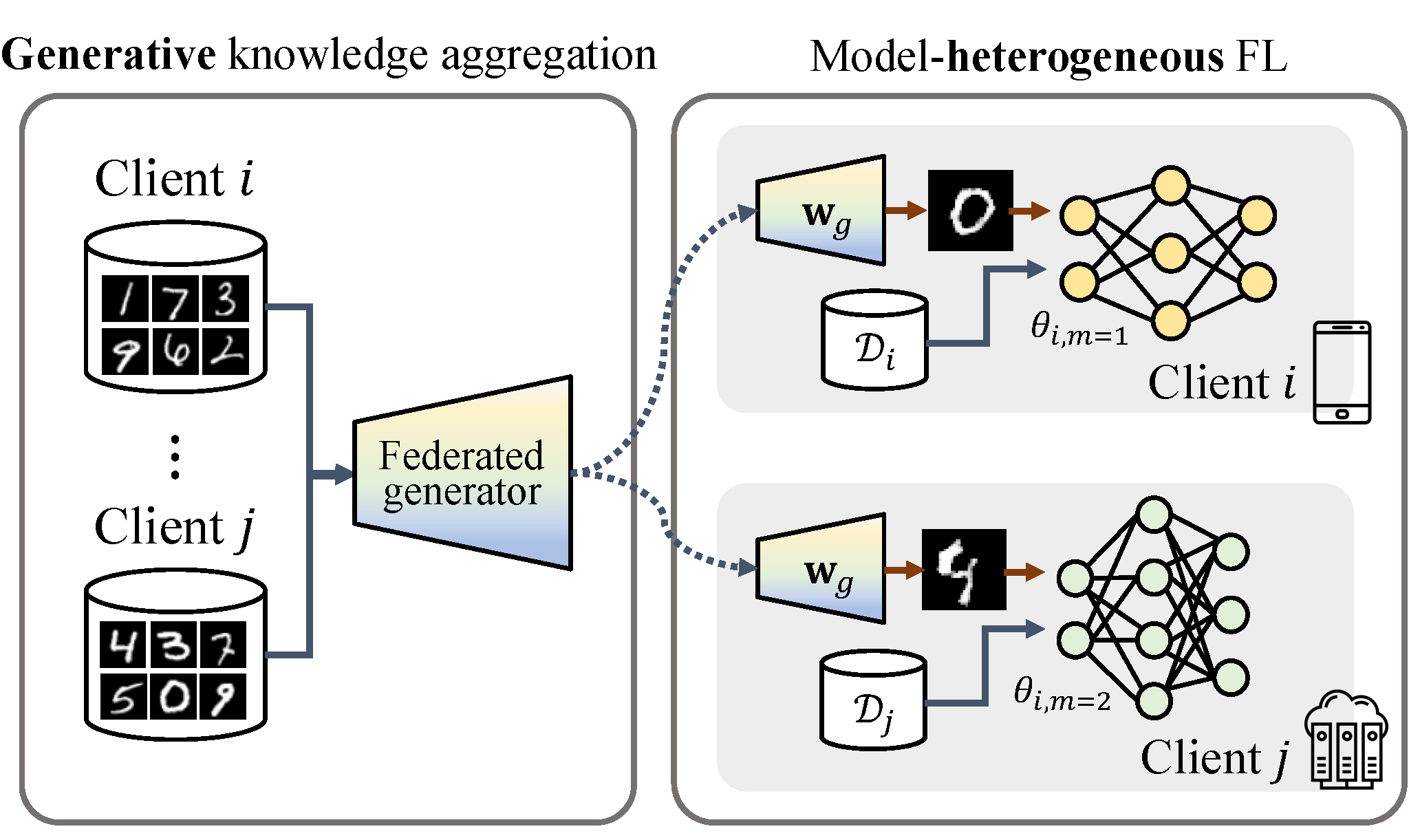
GeFL: Model-Agnostic Federated Learning with Generative Models
Honggu Kang*, Seohyeon Cha*, Jiwan Seo, Joonhyuk Kang IEEE Transactions on Mobile Computing, 2025 paper / project page Federated learning across heterogeneous client models via a shared generative model that aggregates global knowledge. GeFL-F extends this with feature-generative models for stronger privacy and scalability. |
|
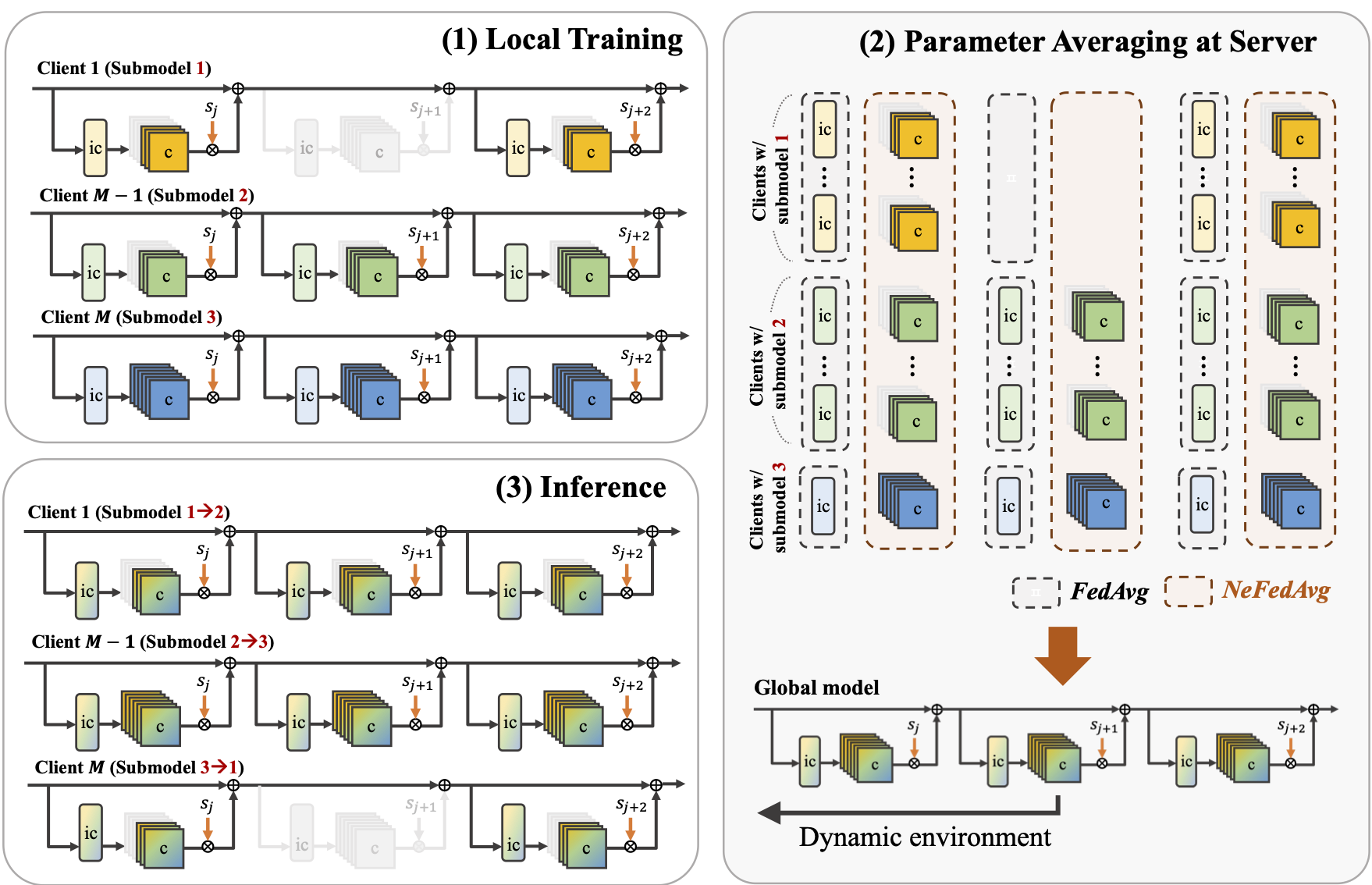
NeFL: Nested Model Scaling for Federated Learning with System Heterogeneous Clients
Honggu Kang, Seohyeon Cha, Jinwoo Shin, Jongmyeong Lee, Joonhyuk Kang IEEE Transactions on Mobile Computing, 2025 arXiv / project page A generalized framework that divides deep networks into submodels via both depthwise and widthwise scaling, interpreting forward propagation as solving an ODE with adaptive step sizes. Decoupled parameters handle inconsistencies when training multiple submodel architectures. |
Conference Papers |
|
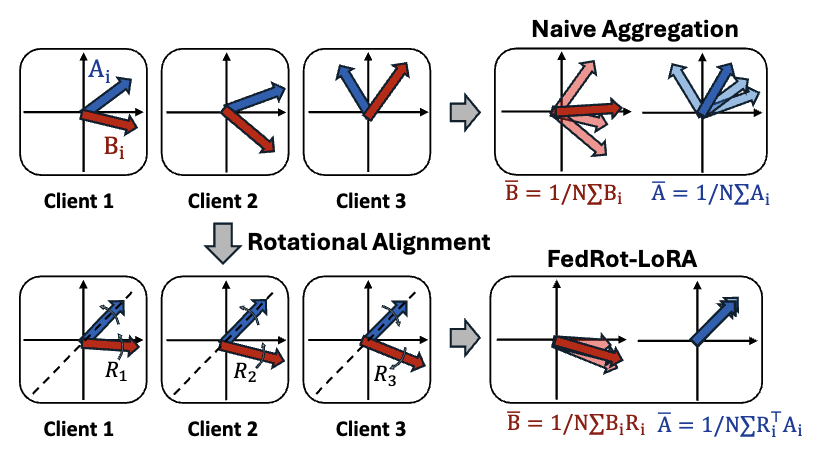
FedRot-LoRA: Mitigating Rotational Misalignment in Federated LoRA
Haoran Zhang, Dongjun Kim, Seohyeon Cha, Haris Vikalo International Conference on Machine Learning (ICML), 2026 arXiv Identifies rotational misalignment between client LoRA factors as a source of degraded aggregation in federated fine-tuning, and introduces a rotational alignment step that preserves the semantic update while reducing cross-client mismatch. |
|
Quantized Gradient Projection for Memory-Efficient Continual Learning
Dongjun Kim, Seohyeon Cha, Huancheng Chen, Chao Wang, Haris Vikalo International Conference on Learning Representations (ICLR), 2026 OpenReview Memory-efficient continual learning via basis-wise quantization of the gradient projection subspace, with quantization-error-aware projection that relaxes orthogonality to compensate for compression error. |
|
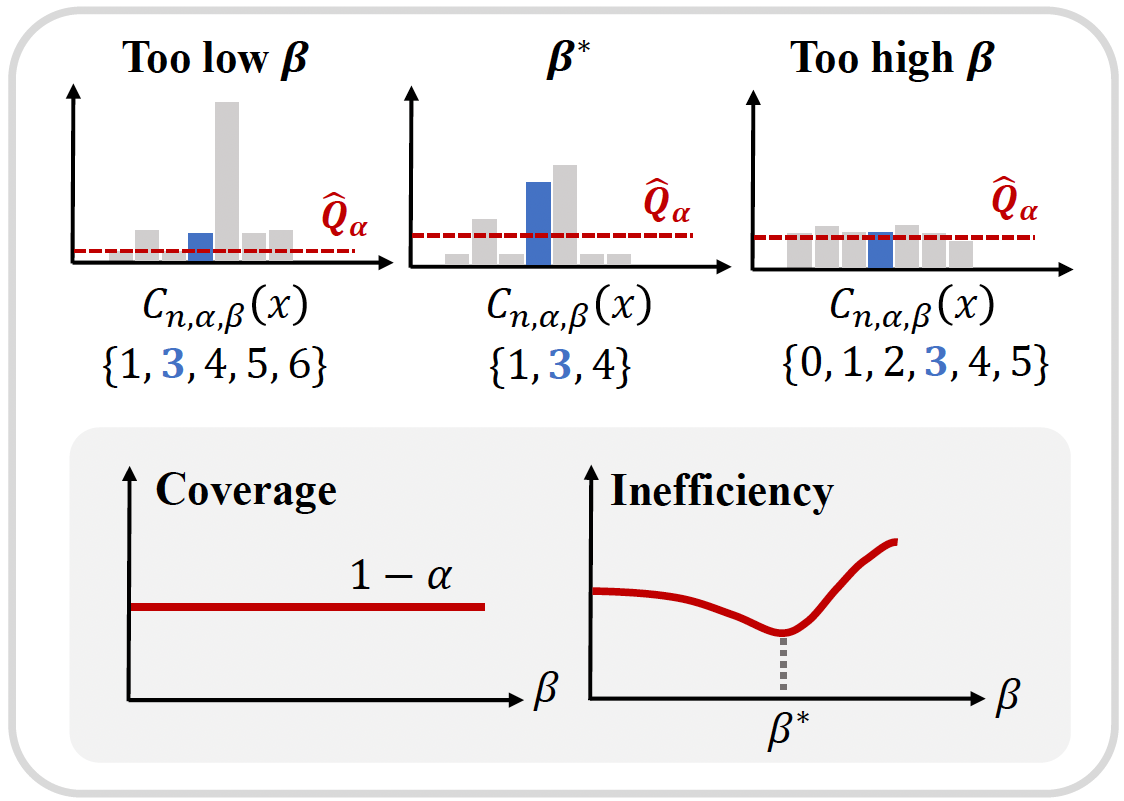
On the Temperature of Bayesian Graph Neural Networks for Conformal Prediction
Seohyeon Cha, Honggu Kang, Joonhyuk Kang NeurIPS 2023 GLFrontiers Workshop paper Introduces a temperature parameter into Bayesian GNNs within conformal prediction, empirically showing temperatures that produce more efficient prediction sets and clarifying the link between CP efficiency and model calibration. |
|
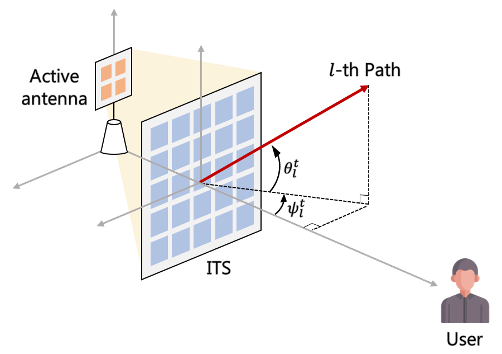
Intelligent Surface-aided Transmit-array Antenna in mmWave Communication System with Historical Channel Observation
Seohyeon Cha, Sanghyuk Kim, Jiwan Seo, Joonhyuk Kang IEEE ICCE-Asia, 2022 paper A stochastic-gradient-descent scheme that optimizes the phase-shift matrix of an intelligent transmitting surface in mmWave downlink using only historical channel observations. |
|
Design adapted from Jon Barron's website. |